【读书活动感悟分享】《离群分析》有关第九章时间序列异常检测的读书感想
一、理论
“ 时间连续性”假设是时间序列异常检测的核心前提。时间连续性指正常情况下数据模式不会突然改变,这种连续性在不同数据中表现迥异:时间序列数据(如传感器监测数据)的连续性极强,相邻数据点高度相关,趋势的延续性是常态;而多维流数据(如实时文本流、网络数据)的连续性较弱,单个数据点的独立性更强,仅在整体上呈现微弱的时间趋势(比如某类新闻的出现频率变化)。因此,异常检测的本质是“寻找打破连续性的例外”,而数据自身连续性的强弱,正是选择检测方法的首要依据。
根据数据连续特性的差异,时间序列异常检测分为两大核心方法——基于预测的偏差检测与基于形状的异常检测。这两种方法从不同维度切入时序数据的规律本质,既各有侧重又相互补充。
基于预测的偏差检测,其核心逻辑建立在 “时间连续性” 这一朴素而强大的假设上:正常时序数据的趋势不会突然断裂,历史规律会大概率延续到当前。这种方法的精妙之处在于将“异常判定”转化为“预测误差的量化分析”。它先通过 自回归模型(AR)、自回归移动平均模型(ARMA) 等模型挖掘数据的跨时间相关性,比如用 AR 模型学习前p 个时间窗口的历史值与当前值的线性关系,或用ARMA 对非平稳序列差分去趋势后再建模,甚至可利用多个相关时序数据的跨序列相关性提升预测稳性。训练好的模型会生成每个时间戳的理论预测值,而异常与否,就取决于实际观测值与预测值的偏差—— 当偏差超出正常波动范围,就意味着数据偏离了历史规律。这种方法特别适合识别单个时间点的上下文异常,比如传感器数据的骤升骤降,其逻辑清晰且可解释性强,并点明核心观点“异常源于对历史趋势的违背”。
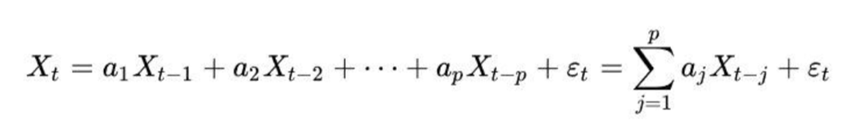
图1 自回归模型公式
而基于形状的异常检测,则跳出了“单个数据点偏差”的局限,聚焦于 “序列整体模式” 的异常。换句话说,有些异常并非孤立点的突变,而是一段子序列呈现出的独特形状—— 比如医疗数据中心律失常的波形、工业设备运行中出现的特殊振动序列。这种方法的核心在于“将形状转化为可对比的特征”:首先对序列归一化处理,消除均值和振幅差异的干扰,再通过数值多维转换、符号离散化等方式,将子序列转化为向量或号表示,把“形状对比” 转化为 “特征相似度计算”。随后,通过基于高阶模板的时序异常检测算法(Hotsax)等基于距离的方法、隐马尔可夫模型等概率模型,或核 主成分分析(PCA) 等线性模型,学习正常序列的形状分布。当目标子序列与正常形状的相似度低于阈值,就判定为集体异常。这种方法的智慧在于抓住了“模式一致性” 这一关键,它不纠结于单个点的波动,而是关注“一段数据的整体是否符合常态”,完美弥补了前一种方法在集体异常检测中的不足。
图2 序列异常数据
上述两种方法从局部偏差和整体模式两个角度解读异常,共同诠释了时序异常检测的核心是“精准匹配数据的规律特性”。通过捕捉单个点的突发偏差,或者识别一段序列的特殊形状,检测出区别与“正常规律”的点或区间即可视为异常。
二、读书感悟
读完《离群分析》第九章关于时间序列异常检测的内容,我深刻意识到将其用于车型曲线异常检测兼具科学性与合理性。车型曲线,又(SOC、Power)曲线,天然具备时间序列“时间连续性”核心特征,其“恒流充电→恒压充电→涓流充”的固定阶段规律,与书中“正常数据存在稳定模式,异常是模式破坏”的核心逻辑高度契合。
上下文异常检测中,自回归模型对 “跨时间相关性”的捕捉,恰好适配车型曲线中前序数据与当前状态的关联;集体异常检测的 “形状分析” 思路,能解决车型曲线不同阶段的异常形态识别问题。这种技术迁移并非简单套用,而是基于两者在“时序关联性”“模式稳定性” 上的本质共性,既遵循时间序列异常检测的科学框架,又能精准匹配车型曲线的特性,为后续技术落地提供了扎实的理论支撑。