【读书活动感悟分享】《SRE: Google运维解密》 第20章-负载均衡
一、本章大纲
1、理想情况
2、识别异常任务:流速空值和跛脚鸭任务
2.1异常任务的简单应对办法:流速控制
2.2一个可靠的识别异常任务的方法:跛脚鸭状态
3、利用划分子集限制连接池的大小
3.1选择合适的子集
3.2子集选择算法一:随机选择
3.3子集选择算法二:确定性算法
4、负载均衡策略
4.1简单轮询算法
4.2最闲轮询策略
4.3加权轮询策略
二、本章内容
(一)理想状况
在理想情况下,某个服务的负载会完全均匀地分发给所有的后端任务。在任何一个时间点,最忙和最不忙的任务永远消耗同样数量的CPU。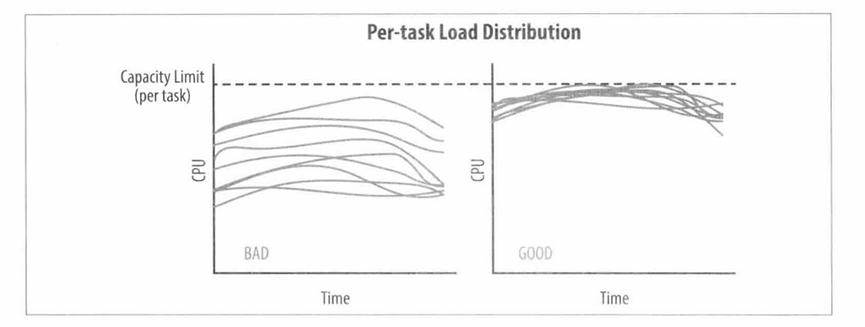
(二)识别异常任务
识别并且避开在后端任务池中处于不健康状态的任务。
2.1 异常任务的简单应对办法:流速控制
客户端任务会跟踪记录发往每个后端的请求状态。当某个后端的活跃请求达到一定数量时,该客户端将该后端服务器标记为异常状态,不再给它发送请求。
缺点:无法应对过载、长连接导致的资源空闲
2.2 一个可靠的识别异常任务的方法:跛脚鸭状态
任务的三种状态
健康
拒绝
跛脚鸭状态:后端任务正在监听端口,并且可以服务请求,但是已经明确要求客户端停止发送请求
这个策略使客户端可以在后端程序进行耗时较长的初始化过程中(这时后端程序还不能服务请求)就建立连接。如果后端程序等到服务可以接受请求的时候才建立链接,就增加了一些不必要的延迟。一旦后端程序可以提供服务了,它就会主动通知所有客户端。
(三)利用划分子集限制连接池的大小
子集划分:限制某个客户端任务需要连接的后端任务数量。
3.1 选择合适的子集
2个考量维度
每个客户端任务需要连接的后端数量(子集大小)
客户端任务请求后端子集的算法
算法要求:
将后端平均分配给客户端,以优化资源利用率
可以自动处理重启和任务失败,持续不断地均衡后端任务,同时避免大幅变动
处理客户端程序和后端程序集群的大小调整,应对后端任务集群滚动重启(例如升级)。在后端任务滚动重启时,我们需要客户端任务持续服务,对重启透明,同时连接的变动最小。
3.2 子集选择算法一:随机选择
让所有客户端任务将后端列表随机排列一次,同时将其中的可解析/可服务状态的后端提取出来。
优点
一次性随机排列并顺序选取可以很好地处理重启和任务失败情况。
缺点
负载非常不均衡
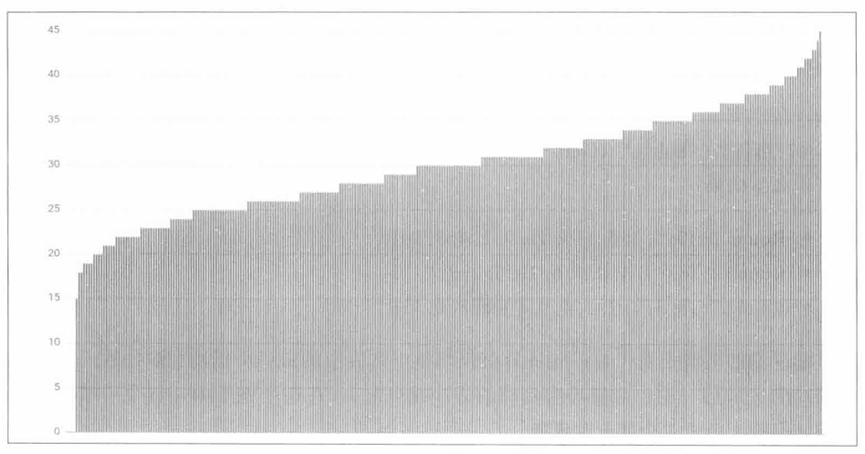
下图描述了如果子集大小降低为10%(每个客户端连接30个后端)的情况。在这种情况下,最低负载的后端只接受平均值的50%(15个连接),而最高负载的后端接受了平均值的150%(45个连接)。
3.3 子集选择算法二:确定性算法
将客户端任务划分在多"轮"中,每一轮i包含了subset_count个连续的客户端,从客户端subset count*i开始,同时subset count是子集的个数(也就是后端数量除以想要的子集大小)。在每一轮计算中,每个后端都会被分配给一个而且仅有一个客户端任务。
(四)负载均衡策略
4.1 简单轮询算法
每个客户端以轮询的方式发送给子集中的每个后端任务,只要这个后端可以成功连接并且不在跛脚鸭状态中即可。
缺点:负载均衡结果很差。
影响因素
子集过小
请求处理成本
不同物理服务器的差异
无法预知的性能因素(物理服务器上的坏邻居、任务重启时的资源开销)
4.2 最闲轮询策略
每个客户端跟踪子集中每个后端任务的活跃请求数量,然后在活跃请求数量最小的任务中进行轮询。
缺点
活跃请求的数量并不一定是后端容量的代表。等待网络请求长于实际运行时间
每个客户端的活跃请求不包括其他客户端发往同一个后端的请求
4.3 加权轮询策略
每个客户端为子集中的每个后端任务保持一个“能力”值。请求仍以轮询方式分发,但是客户端会按能力值权重比例调节。在收到每个回复之后(包括健康检查的回复),后端会在回复中提供当前观察到的请求速率、每秒错误值,以及目前资源利用率(一般来说,是CPU使用率)。客户端根据目前成功请求的数量,以及对应的资源利用率成本进行周期性调节,以选择更好的后端任务处理。失败的请求也会记录在内,对未来的决策造成影响。
三、心得体会
1、如何限流。资源消耗大的并不一定是QPS高的,如请求中包含性能差的SQL读取,此时服务器CPU、内存都相对闲置,要避免这种请求长期占用端口资源,如何识别出这类请求,并通过设置较小的流控阈值保护端口数。
2、对谁限流。资源永远稀缺,限制非核心服务,保核心服务。
3、通过熔断保证其它服务可用性。
4、HSF请求随机路由的缺陷,客户端无法探知服务端压力状况。目前HSF请求方通过定时TCPPing来探测服务端可用性(健康检查),无法获知服务端当前压力,可能请求到已经出现资源瓶颈的服务端。
5、跛脚鸭状态的借鉴意义。HSF服务端重启前停止接收新请求,但仍处理完存量请求。
6、HSF支持权重设置,当前阶段可基于CMDB进程注册信息中权重属性。
7、 对Nginx反向代理的借鉴意义
a)后端站点定时健康检查(被动式,避免影响Nginx运行时性能)
b)后端站点定时压力检查(被动式,动态调整权重)
c)后端站点的服务异常熔断(主动式,摘除SG服务路由)