【读书活动感悟】—特无忧—《理解栈与堆》掌握内存管理、调试崩溃、优化性能的基础
栈(Stack)和堆(Heap)是程序运行时管理内存的两种核心机制,它们在分配方式、生命周期、性能、用途等方面有本质区别。
一、基本概念
栈是一种非常简单的数据结构,它类似于一叠纸。每增加(压入)一张纸时,这张纸都将被放在这叠纸的顶部。而每取走(弹出)一张纸时,都是从这叠纸的顶部取走的。同理,在栈中也会执行压入/弹出这两个基本操作,并且这两个操作也都是在栈的顶部进行的。由于每张纸都是在顶部被增加或者取走的,因此这个算法也称为后进先出(LastInFirstOut,LIFO)算法。
在Windows中,栈只是操作系统为线程分配的一块内存。栈的作用是记录函数调用链(包括局部变量的分配、参数传递等)。每当调用函数时,都会创建一个栈帧并且将其压入到栈中。随着在线程中调用越来越多的函数,栈也会变得越来越大。下面图就说明了在函数调用中的栈结构(x86架构上的调用函数栈)。

堆(heap)是一种内存管理器,程序可以通过堆来动态的分配和是释放内存,通常,程序使用堆的情况包括,当无法预先知道所需的内存大小或者所需内存过大而无法在栈中进行分配(自动内存)。尽管堆是实现动态内存分配的最常见方式,但程序也可以通过其他方式来从Windows中请求内存。程序可以从C运行时、虚担内存管理器,甚至其他形式的私有内存管理器中获得内存。虽然不同的内存管理器都被视作为独立的实体,但它们本质上是密切相关的。
二、特性对比
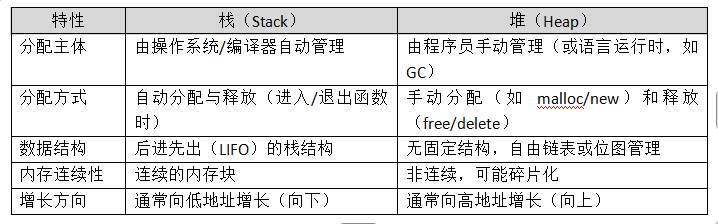
三、关键区别详解
1. 生命周期
栈:与作用域绑定。
局部变量、函数参数在函数调用时入栈,函数返回时自动销毁。
C示例:
void func()
{
int a = 10; // 入栈
} // a 自动出栈,内存回收
堆:动态生命周期,直到显式释放或程序结束。
C示例:
int* p = malloc(sizeof(int)); // 分配到堆
*p = 10;
free(p); // 必须手动释放,否则内存泄漏
说明:C# / Java 等语言中,堆对象由垃圾回收器(GC)自动回收,无需手动 free。
2. 访问速度
栈更快:
1) 内存连续,CPU 缓存友好
2) 分配只需移动栈指针(1 条指令)
堆较慢:
1) 需查找空闲块、维护元数据
2)可能触发系统调用(如 sbrk/mmap)
3. 大小限制
栈小:
1) 通常几 MB(Linux 默认 8MB,Windows 1~2MB)
2)过深递归或大局部数组 → 栈溢出(Stack Overflow)
堆大:
1) 受限于虚拟内存(32 位约 3~4GB,64 位极大)
2) 可分配大对象(如大数组、复杂对象树)
4.存储内容
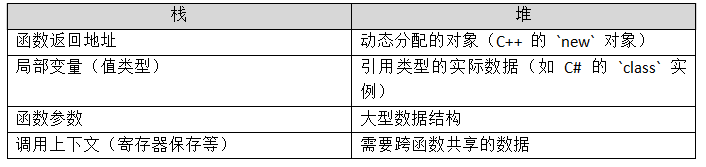
在 C# / Java 中:
值类型(int, struct)默认在栈上(若未被闭包捕获或装箱)
引用类型(class) 对象本体在堆上,栈上只存引用(指针)
5. 安全性
栈:安全--自动管理,不易出错(除非溢出)
堆:易出错- 内存泄漏(忘记 `free`)、 悬空指针(释放后继续使用)、重复释放(double free)、缓冲区溢出(越界写破坏堆结构)
现代语言(Rust、C#、Java)通过所有权、GC、边界检查大幅降低堆风险。
四、示例对比(C 语言)
C语言示例
void example() {
int a = 10; // 栈:自动管理
int* p = malloc(4); // 堆:手动管理
*p = 20;
printf("%d %d", a, *p);
free(p); // 必须释放堆内存!
} // a 自动销毁,p 指向的内存若未 free 则泄漏
总结:
栈用于短期、自动管理的小数据;堆用于长期、动态分配的大数据。
栈是“纪律严明的士兵”,堆是“自由但需自律的公民”。