【读书活动实用案例分享】《SRE: Google运维解密》:Redis运维
读完《SRE Google运维解密》之后,最大的收获是深刻理解了SRE工程师的职责与理念:职责是用工程化方法保障系统的可靠性,理念是“以软件工程的方式解决运维问题”,核心在于可靠性优先、自动化、可观测性和持续改进。
这些理念不仅是理论,更能指导我们在日常工作中解决实际问题。下面结合我在书中体会到核心思想, 分享下我在Redis 运维中的两个案例。
案例一:Redis 版本升级(3.2.12 → 6.0.12)
背景问题:
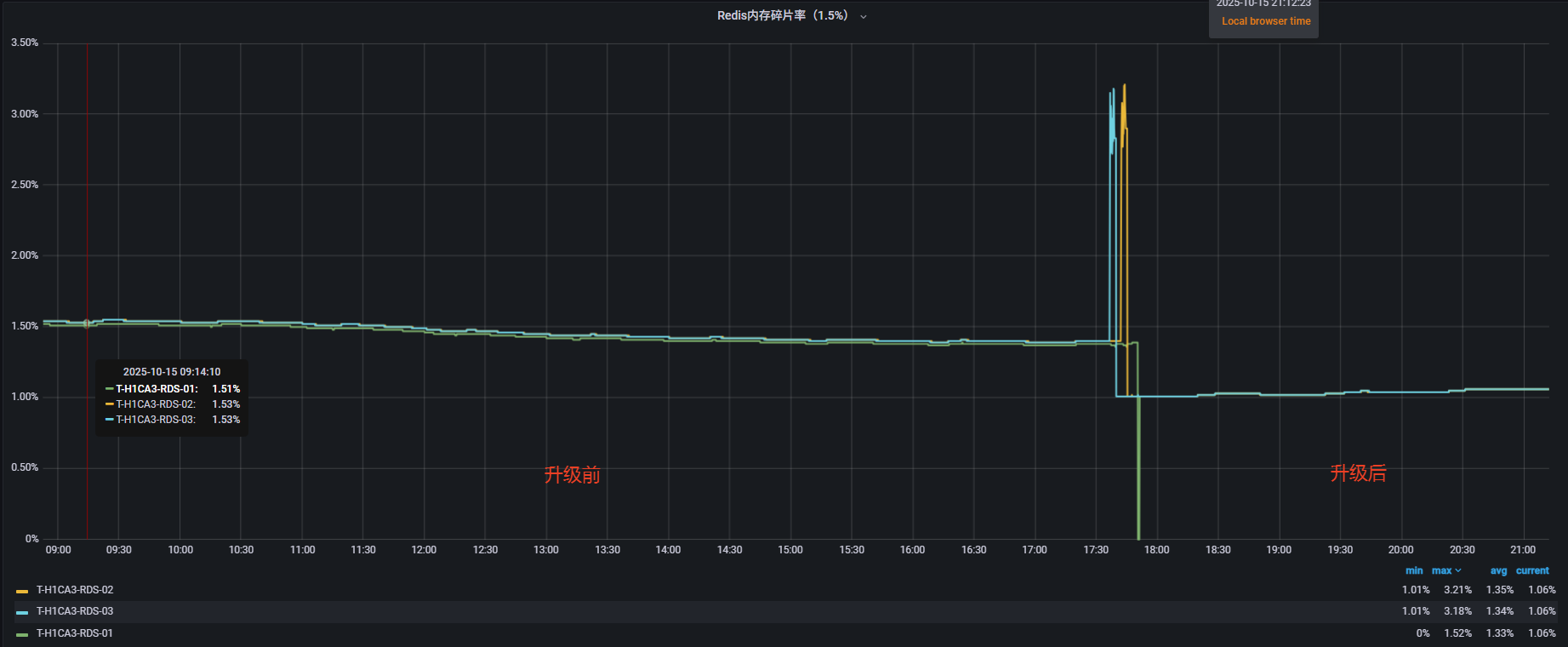
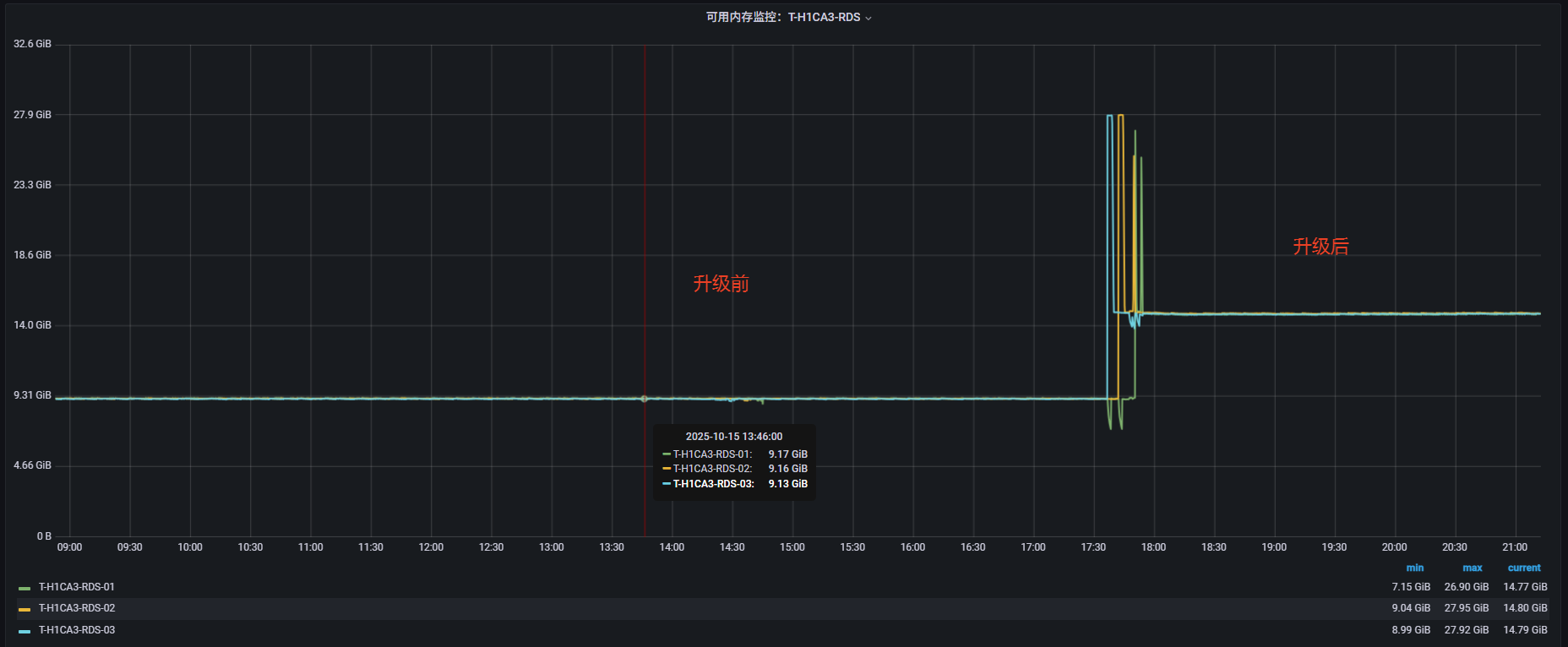
在 Redis 3.2.12 版本中,内存碎片无法自动回收。随着服务长时间运行,碎片不断累积,即使清理缓存数据,内存占用也无法有效降低,最终只能通过重启Redis 服务或迁移来解决问题。然而,当内存持续上涨到一定程度时,还会进一步影响 Redis 的持久化操作。对于生产环境中的核心集群而言,服务重启或宕机是不可接受的风险。因此,为了避免潜在的灾难性故障,遵循SRE“可靠性优先”理念,必须对Redis进行版本升级,从根本上提升系统的稳定性与可靠性。
解决方案:
借助Redis哨兵集群主从切换,从Slave节点到Master节点逐个升级到Redis 6版本,启用 active defrag 功能,支持自动内存碎片回收。
具体升级步骤可查阅:2025-09-17_合肥环境Redis版本升级
效果与收益:
版本升级后,Redis内存碎片率得到显著降低,服务器可用内存由9G提高到14G,减少了5G内存的占用,内存利用率显著提升,服务稳定性大大提高。
案例二:C# 插件采集 Redis Slowlog 并预警
背景问题:
Redis 的慢查询(Slowlog)是其内置的性能诊断机制,用于记录 执行时间超过指定阈值的命令,帮助开发者和运维人员分析性能瓶颈、定位异常命令以及监控大 Key 操作。但是Slowlog 仅以循环队列的形式存储在内存中,日志条目数量受配置限制,超过上限后旧记录会被自动覆盖。因此,若不进行额外的持久化处理,慢查询日志无法长期保存。在实际运维场景中,这意味着当问题发生时,往往难以获取完整的现场数据,增加了排查和定位的难度。
解决方案:
- 使用 C# 编写监控插件,定期采集 Redis Slowlog。
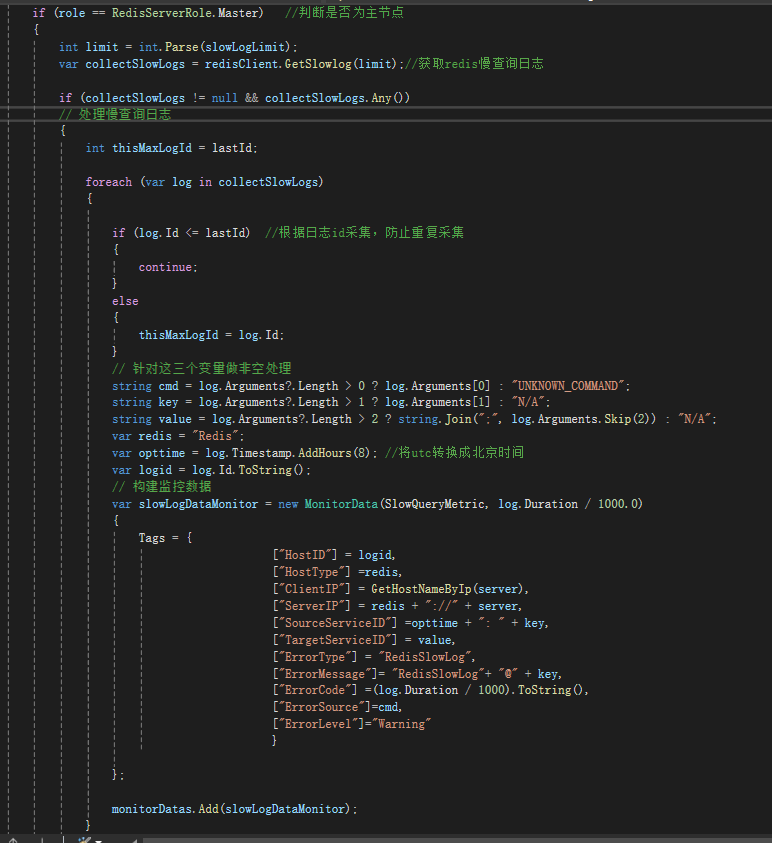
- 将数据推送到监控系统(ES、Grafana)。
- 设置阈值和告警规则,实现自动预警。
效果与收益:
- 慢查询问题可以实时发现并预警,避免影响业务;

- 自动化监控减少了人工排查,提升了运维效率;
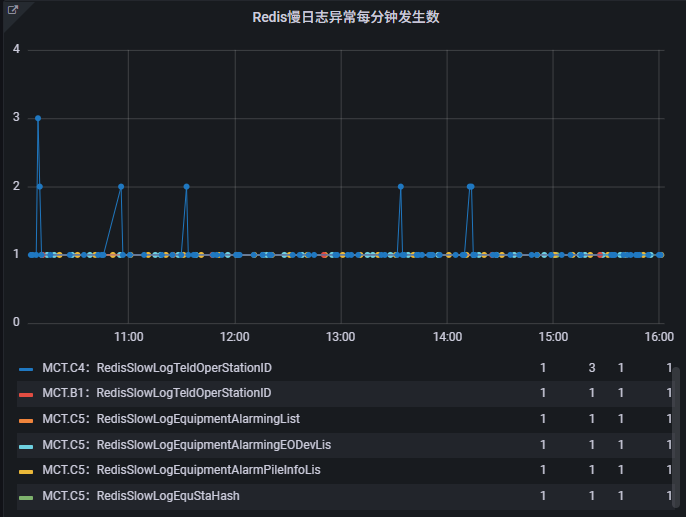
- 符合SRE “持续改进” 的思想:登记行动项,推动程序持续改进;

总结:
这两个案例分别体现了 SRE 的不同核心理念:
- Redis 升级:可靠性优先,将能预知的故障扼杀在摇篮里。
- Slowlog 监控: 监控与可观测性+自动化预警+持续改进。
共同点在于:通过主动改进和自动化手段提升系统可靠性,并建立可观测性体系推动持续优化。这正是《SRE Google运维解密》所强调的核心价值:
- 运维不再是被动的“救火”,而是主动的可靠性设计与改进;
- SRE 的职责不仅是保障系统稳定运行,更是通过监控和自动化手段,推动团队在可靠性与效率之间找到平衡。