【读书活动实用案例分享】《SRE: Google运维解密》:基于时间序列数据监控预警的应用实践
读完《Google SRE 运维解密》后,书中关于“基于时间序列数据进行有效报警”的理念一直让我印象深刻。作为平台技术部-运维保障团队的一员,我们的职责范围不仅覆盖特来电生产环境,还延伸至数十个独立及混合部署的项目。为这些繁多的环境配置有效的监控预警,一直是我们工作的核心挑战与长期投入的重点。
曾几何时,我们被凌晨发生“CPU打满”、“磁盘告急”的电话、钉钉信息支配,疲于奔命。堆砌了无数的监控图表,但很多时候却依然像是在迷宫里打转,看不清系统的全貌,更无法回答那句话:我们的系统到是底稳定还是不稳定?
正是这次读书活动,对《SRE Google运维解密》的深入学习,尤其是第十章《基于时间序列数据进行有效报警》。它让我们意识到,问题的根源在于我们的监控预警不能仅停留于资源导向,更要上升到业务层面来建立。如果不进行这一关键跨越,非常容易陷入“只见树木,不见森林”的困境,即使每台服务器的资源指标都看似正常,整个服务却可能因性能瓶颈而不可用。
一、统一的数据底座
在我们早期的环境部署工作时,已经打下了良好基础。在生产环境和各个项目环境中,我们广泛使用了telegraf、monitoragent、埋点等方式,将服务器、中间件、数据库、业务应用的指标统一写入InfluxDB、Prometheus中,并通过Grafana进行展示。这套体系解决了“有数据”的问题。
但很快我们发现了瓶颈:资源导向的监控预警让我们在排查一个业务故障时,始终要像一个侦探一样,在几个甚至几十个图表中串联线索,提取关键信息。
二、从“机器指标”到“业务洞察”的关键跃迁
通过对第十章的阅读,让我们明白监控的价值在于揭示对业务的影响。我们不应仅满足于机器是否存活,而是聚焦于业务是否健康。这一转变有三个关键分析来实现:
1、核心业务受损
我们意识到,仅当业务流量已经暴跌时才报警,损失已然发生。为此,我们为核心业务链路引入了智能预测模型。同时与业务团队的深入沟通交流,共同识别了系统中的核心业务链路,例如“用户从登录到完成充电”的完整流程。结合InfluxDB的连续查询功能,并利用DNN、Prophet、LightGBM等模型进行时间序列预测,生成未来一段时间内业务流量的合理区间带,以此来提前感知业务流量的异常衰减或骤增。
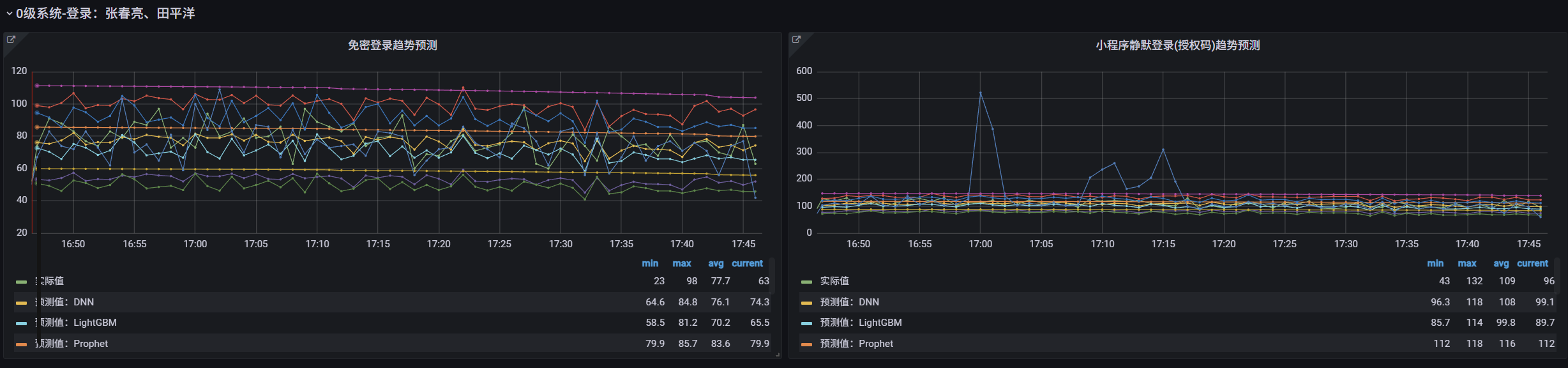
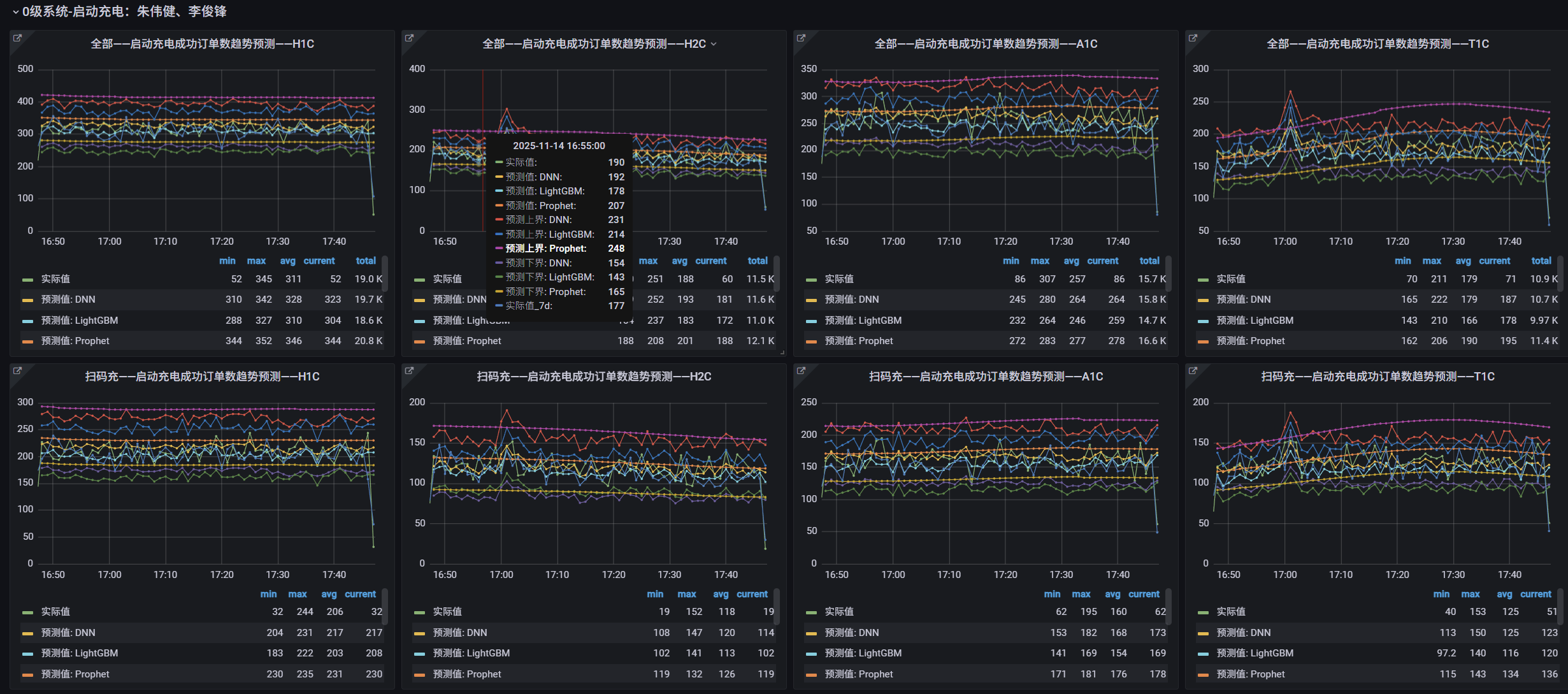
2、异常聚类分析
在应用日志中,各种错误和异常司空见惯,如何从成千上万条日志信息中提取归纳出有用的关键点,是分析判断业务异常的关键。我们按照数据中心、服务单元、应用集群等多种维度对上报的异常信息进行了聚类分析,写入到InfluxDB,并由Grafana进行展示,这样即可将我们需要寻找的关键信息在背景噪音中分离出来,能够指引我们迅速发现问题,避免后续的服务雪崩。
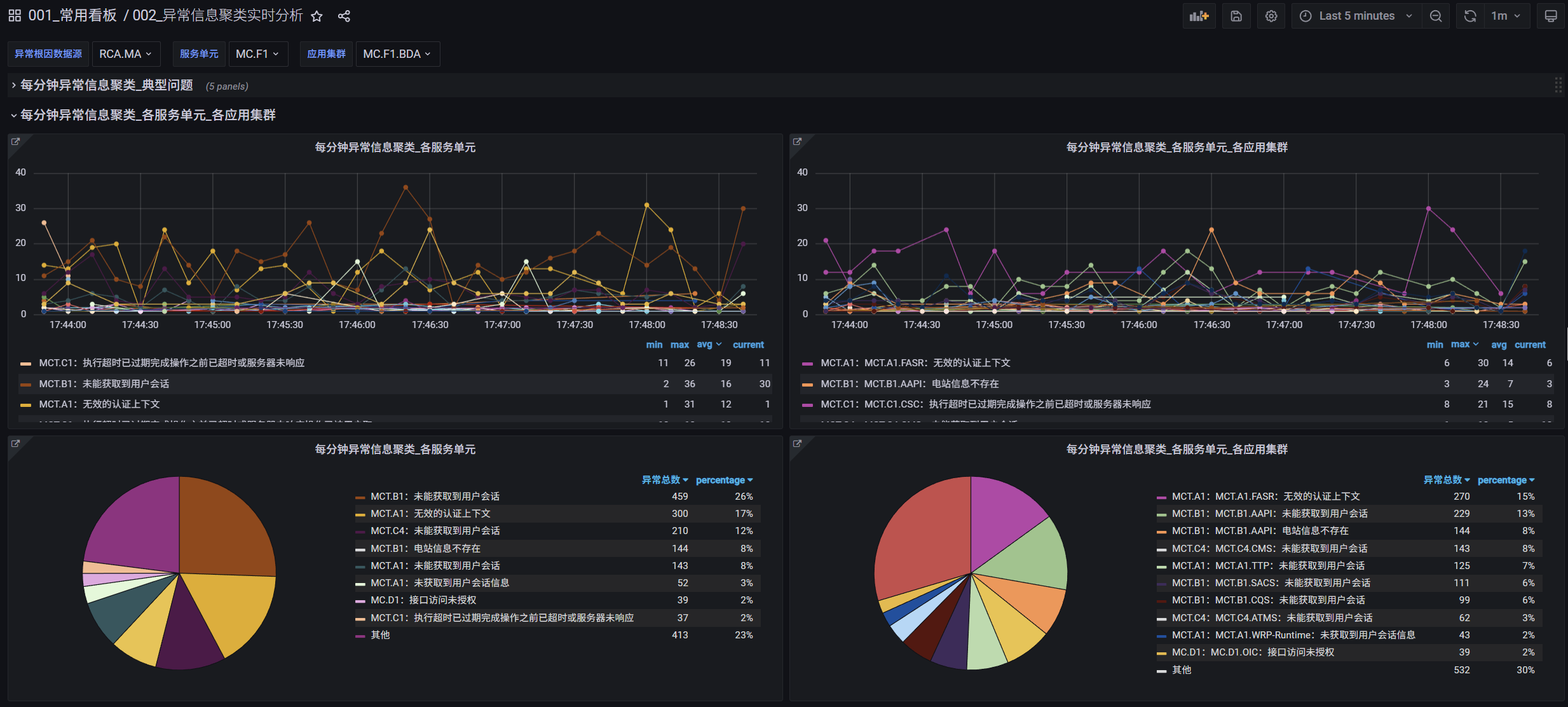
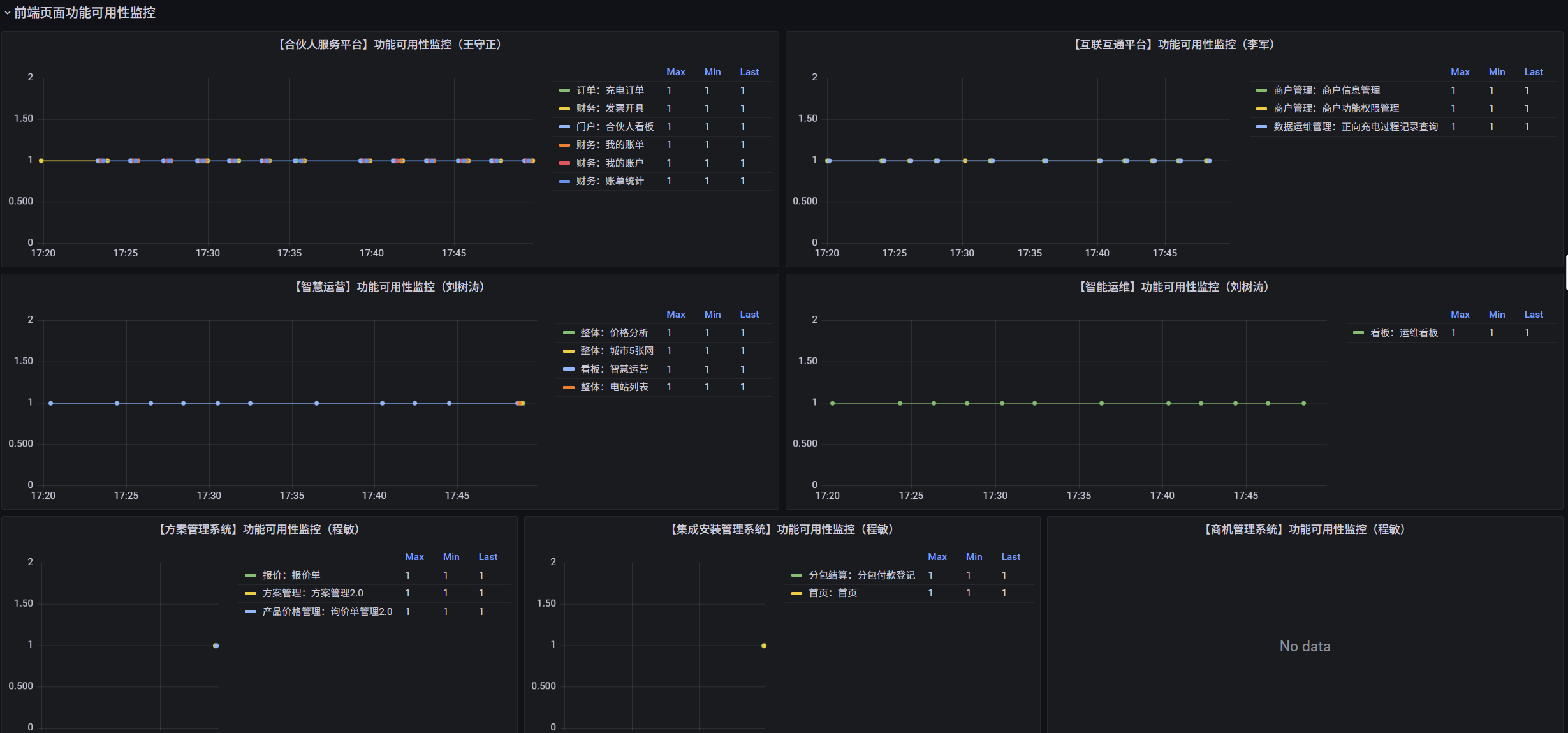
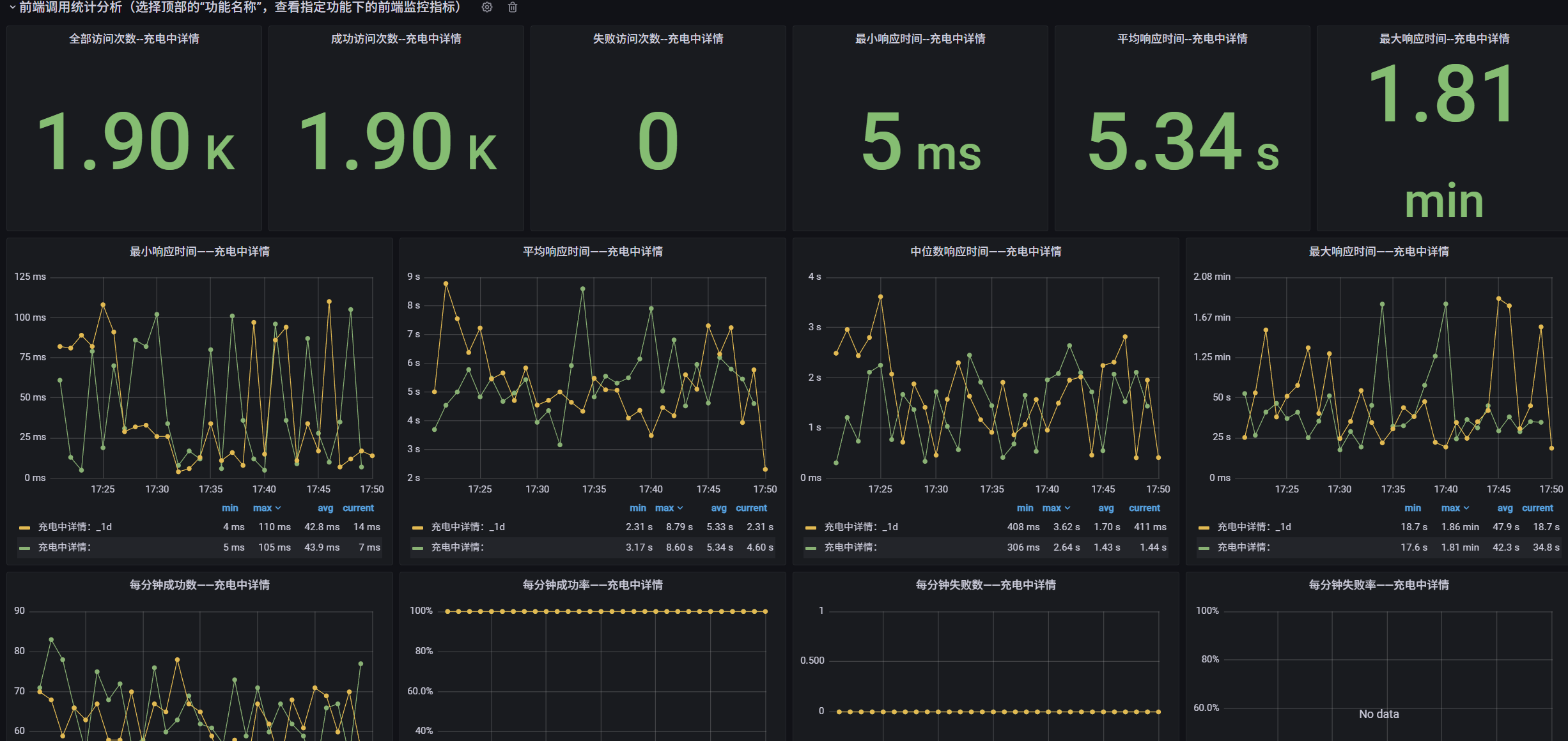
3、前端性能分析
后台服务一切正常,并不能代表用户用的一切顺畅。收集并分析前端性能数据,将成功/失败的访问次数、关键功能操作的响应时间等指标纳入统一的监控体系。并按照各个功能模块进行聚合分类,能够有效的站在用户角度去感受系统的流畅程度,及时去解决异常服务的性能问题。
总结
有效的报警不在于数量,而在于质量;监控的目标不是展示数据,而是揭示系统对业务的真实影响。现在,我们的InfluxDB中存储的不仅仅是数据,更是我们对系统行为的深刻理解。Grafana上展示的,是一幅幅围绕业务价值构建的服务健康地图。
这套体系让我们从被动的“救火队员”,逐步转变为了主动的“系统守护者”,实现了从“救火”到“防火”的真正跨越。