【读书活动读后感】-bug队-《从Docker到Kubernetes入门与实战》
在团队感悟三中我们已经完成了Windows环境下,K8s+docker部署的小案例。那现在我们必须得重新思考K8s+docker到底能突破哪些瓶颈?在对比到我们现在的工作中有哪些启发?
随着充电业务的发展,例如蜀道会在国庆等长假内出现流量高峰,订单数倍飙升的情况下通过仅有的服务器资源如何弹性支撑充电业务?要做到秒级部署+快速扩容迎接流量爆发借助Docker+K8s,这是概念中提到的优势和价值,读《从Docker到Kubernetes入门与实战》我们更应该深思的是容器化思维,哪些核心业务需要打包镜像避免被抢占资源。
假设有10台服务器16核32G,且核心的订单服务、设备服务、支付结算服务、用户服务、后台服务等可打包镜像。在分配资源之前我们先完成K8s的HPA配置,如订单服务我们基于单量与cpu使用率出发,配置minReplicas与maxReplicas,配置CPU超过80%自动触发,还可以指定periodSeconds分钟级扩容实例数,如后台服务等优先级较低的服务,高峰期时则配置最大实例数为平时的0.8倍,下调内存分配和CPU资源自动缩容。
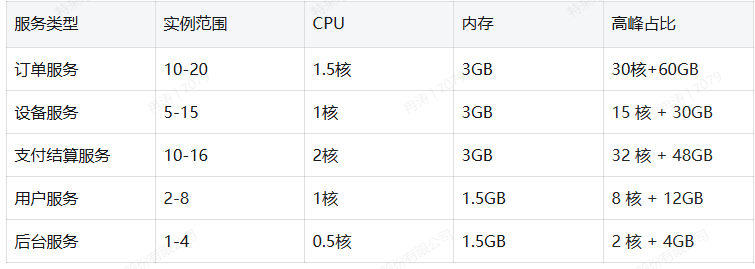
峰值为87占比仅54%,预留的CPU和内存可以用在如上述案例的高峰期进行扩容,当然实际的场景可能更加复杂可能资源的消耗远大于理想。预估分配可以通过上线前的压测和grafana监控数据,我们推算出更加合理的值,完成这个操作也体现了K8s+docker在有限的资源在对资源的合理分配利用,降低成本支出时对业务提供更稳定的支持。
再贴合一下我们对CLP业务支持时遇到的问题,客户不止一次提到过UAT环境和生产环境出现差异,也不止一次提到我们最大能支撑多少笔订单同时充电?换位思考如果是客户如何来评估系统的高可用?怎么实现单节点故障,故障自愈,核心充电到支付流程不中断。前面分享过docker镜像核心保障环境一致性,可以避免我们因为版本、依赖等不一致导致的个性化差异。这里更多分享一下K8s的/health,健康检查。比如我们核心的订单服务因为内存泄露,livenessProbe监测到失活则会秒级重启容器,比如我们的支付服务刚启动,可以通过readinessProbe检测是否就绪避免用户访问超时提高用户体验。同样这也是K8s+docker的核心价值。关于故障自愈与服务故障影导致数据丢失,订单和支付服务被设计为无状态仅处理流程不存储数据,当容器销毁或故障重启时,新的容器启动后可在数据库中拉去数据订单的状态、充电的状态不会丢失。在书中提到了很多应急措施重要保障服务稳定,预警机制+检查自愈机制可以极大的提升解决线上问题的效率,如果能加上应急策略则系统更健壮。
docker与K8s的协同是越来越多企业的事实落地方案,以降本提效为核心助力业务增长。未来我们可能支撑更多设备接入,爆发式的订单增长,为什么选择这本偏向技术推行和实践的书籍,初读时是求知、是博观而约取,深入架构设计它更是高度贴合业务的最佳实践。在未来也应锲而不舍的读书积累,练就穿金碎石的能力。