【读书活动读后感】云平台SRE特战队
直至2025年9月,借公司“阅燃心动·60天共读一本书”活动之机,我与SRE团队重启共读,方真正体会到“初读不识书中意,再读已是书中人”——此言诚不我欺也。
这次共读持续了两个月,我们并不只是为了完成任务,而是想把书里的内容和SRE实际的工作一一对应起来,把过去的经验整理成一套能用的方法。过程很平淡,没什么轰轰烈烈,但收获比想象中大得多。
一、响应号召,迅速启动
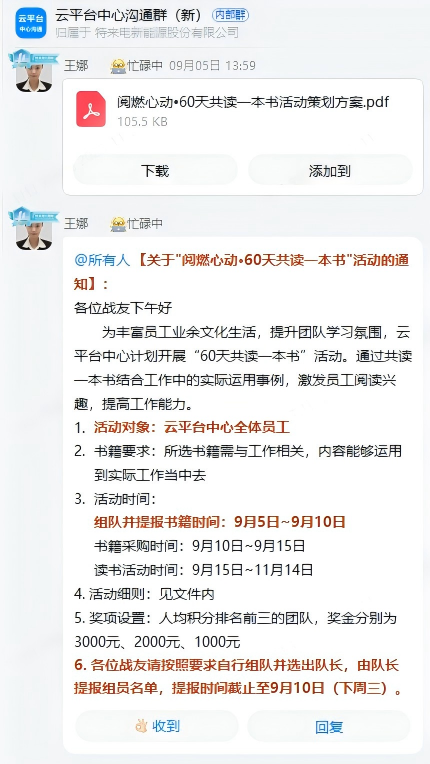
2025年9月5日,看到“云平台中心沟通群”中发布了“关于"阅燃心动•60天共读一本书"活动的通知”:
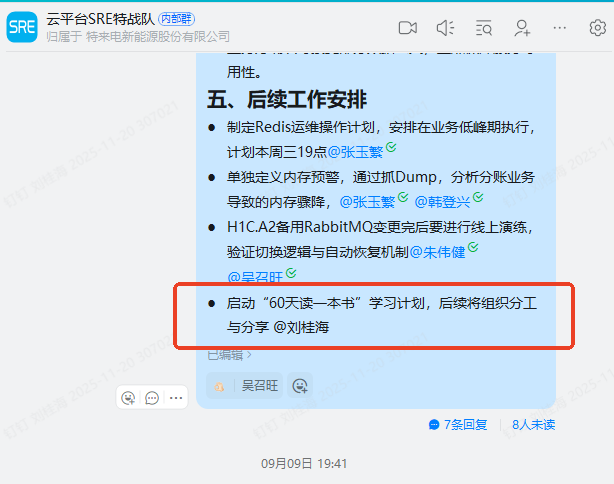
在2025年9月9日,我在SRE群里发了一个公告,计划提报《SRE: Google运维解密》,要求每个SRE人员都要参加:

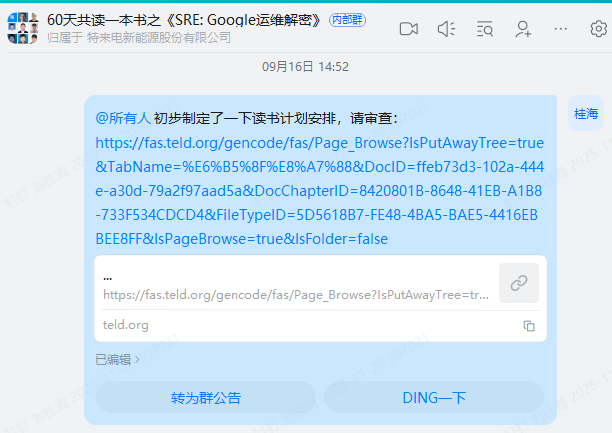
SRE人员比较多,为了能在规定时间内完成《SRE: Google运维解密》的阅读,我们组建了一个”60天共读一本书之《SRE: Google运维解密》”钉钉群:
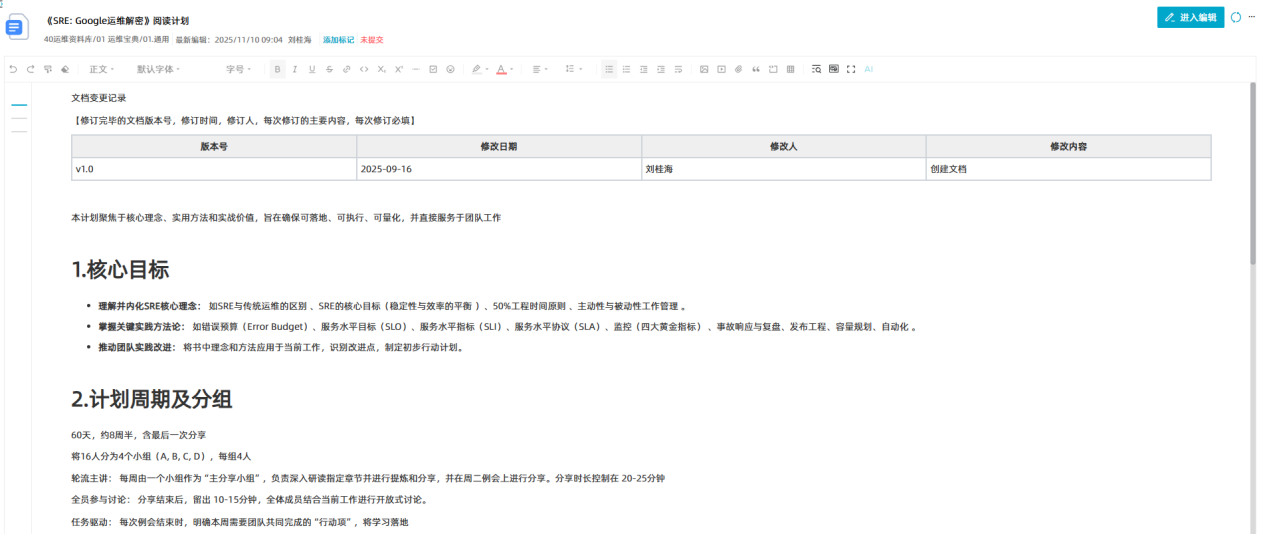
综合考虑了工作地点、工作内容等相关性后,每个组的队员也确定了。
最后是读书内容的安排,借助大模型,将全书25章合理拆分为8周节奏,每章聚焦1–2个核心理念(如SLI/SLO/SLA、错误预算、自动化优先、事后复盘文化等),确保和和工作有交集,保证讨论不流于表面。
一切就绪,每周二SRE周例会的最后一个环节,就是读书分享活动,经过两个月的稳步推进,终于顺利完成了阅读活动。
三、从书本上来,到实践中去
在阅读《SRE: Google运维解密》的同时,我们也在将书中的理论应用到工作实践中:
3.1 运维左移(点击查看)
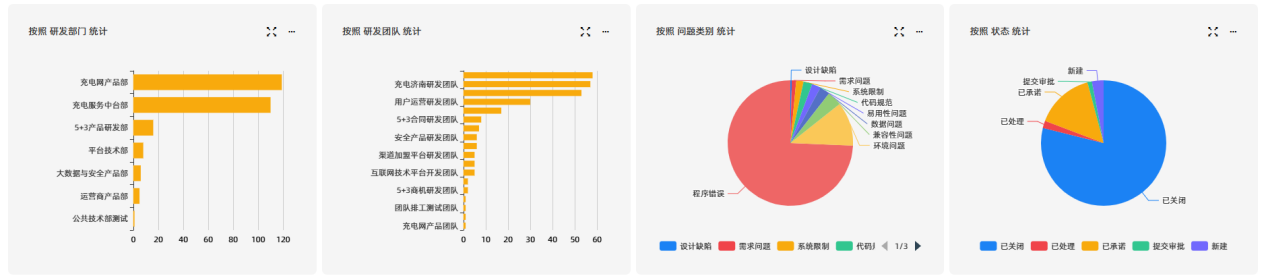
为贯彻落实《SRE: Google运维解密》中“运维应深度参与研发及架构设计,从源头防控隐患”的核心理念,在读书活动期间,平台技术部持续推进“预防优于修复、左移治理风险”的运维转型实践。针对生产环境中高频出现的典型运行时异常,建立自动化缺陷登记与责任闭环机制,显著提升系统健壮性与交付质量。
自该机制上线以来,已自动登记项目库Bug 260+项:
3.2 自动化运维巡检(点击查看)
在每周二SRE周例会上,定时分享《SRE:Google运维解密》过程中,每个SRE人员深刻认同书中“自动化是应对复杂性的唯一出路”这一核心理念。
为提升系统稳定性与运维效率,平台技术部自主研发并落地了运维巡检自动化系统,实现从“人肉巡检”向“智能感知+自动闭环”的关键跃迁。
该系统应用到合肥项目中,目前由6个人参与的周报编写,可以自动生成,极大降低运维工作量,显著提升运维效率,真正的生产力工具!
3.3 Redis运维(点击查看)
读完《SRE Google运维解密》之后,最大的收获是深刻理解了SRE工程师的职责与理念:职责是用工程化方法保障系统的可靠性,理念是“以软件工程的方式解决运维问题”,核心在于可靠性优先、自动化、可观测性和持续改进。
版本升级后,Redis内存碎片率得到显著降低,服务器可用内存由9G提高到14G,减少了5G内存的占用,内存利用率显著提升,服务稳定性大大提高。
3.4 黑盒监控从用户视角感受系统(点击查看)
平台技术部 - 运维保障团队参与特来电充电云平台独立部署和混合部署项目数十个,真正地把黑盒监控从理论落地到实际应用场景中,极大程度上解决了我们多项目并行时 “环境存活状态两眼摸黑” 的痛点。
3.5 让Dump分析闭环(点击查看)
平台运维监控提供了Dump分析功能,支持对CPU高、内存高、活跃线程数高、CLR异常等典型场景抓取并分析Dump,但是抓取Dump后,缺少分析Dump的跟踪机制,导致问题无法闭环处理。
该功能实现了Dump分析支持自动登记预警工单功能,极大提升了运行时问题闭环率。
3.6 主动治理影响系统稳定的隐患(点击查看)
7.31架构升级迁移完后,经过一段时间的环境治理,主机资源利用率趋于稳定,以下是针对监控组件的治理总结:
云服务商监控组件:
1. 华为云:UniAgent:占用句柄数高
2. 华为云:telescope:占用CPU高
IT基础设施监控组件
1. ZabbixAgent:占用句柄数高
2. Fluentbit:占用内存高、疯狂写message日志
3. CloudWalker:占用内存高、占用CPU高、ioi_wait高
四、阅读感悟:凝心聚力,聚沙成塔
4.1 A组
4.1.1 代冰
《SRE: Google运维解密》是一本除了语言工具、技术框架等技术书籍外,少数的读起来感觉跟实际工作如此贴近的书籍之一。通过对这本书的阅读,了解了SRE的起源,Google SRE团队在相关工作中走过的弯路和相关的最佳实践。SLA目标,预警体系,值班机制,故障复盘,自动化运维等该有的主要流程我们都已具备,但在一些点上还需要结合我们的实际情况细化,完善,创新。
4.1.2 张宁涛
《on-call轮值》启示我们,虽然on-call字面意思是让运维人员实时监控系统的运行情况,但最终目的还是为了解放人工,重点强调使用“工程化思维”,解决“人的问题”,通过量化指标、流量工具和文化建设等手段,将“被动响应”转化为“主动优化”,最终实现系统的高效平稳运行。
《紧急事件响应》启示我们,故障是“系统的体检报告”,更是“团队的成长阶梯”。通过科学有效的响应、坦诚的复盘和主动的测试,让每次故障都成为系统更稳定,更可靠、团队更专业的“垫脚石”。
4.1.3 张建利
60天共读《SRE》的进程里,第12章“有效的故障排查手段”读后,结合公司监控运维技术体系,感觉非常有共鸣及带入感,
以前碰上个预警消息炸屏的情况,我们总下意识“头痛医头”:看见慢查询报警就扎进数据库,折腾半天发现方向全错。我们可以结合书中“假设-排除”的思路:先看Grafana看板,发现是应用服务器CPU骤升而非数据库瓶颈,这就排除了之前常犯的“惯性归因”陷阱。接着调全链路监控,很快定位到新上线的库存校验接口有异常调用,再用自动抓dump拿到的堆栈信息一比对,非常快速的定位的问题发生的根本原因。
周例会问题分析及故障复盘时,大家都提到这章的启发——以前我们只说“解决了什么”,现在会主动复盘“哪步假设错了”“哪个工具帮我们缩短了排查时间”。原来SRE的故障排查不只是靠“直觉”,而是用系统化方法把Grafana、全链路监控这些工具串成闭环,这大概就是共读最实在的收获吧。
4.1.4 李灯泰
通过拥抱风险这个章节的介绍,作为 SRE的一员,从中得到一些收获及对此前工作的深入理解,最大的收获是学会用量化风险的方法去评估平台的可靠性,就像针对可用性指标设定合理的量化值,就如对核心业务做业务受损的检测,通过具体的量化指标反向平台的的稳定性;也可以用量化值去管理风险:针对核心服务的调用成功率,可以通过不同维度去设置容量,容量剩余越少,说明服务的可靠性越差,云平台也可以从这个方面着手去做一些风险管理,这样能更好的去管理风险,也对云平台的全年的SLA做一个管控。
4.2 B组
4.2.1 朱伟健
《SRE:Google运维解密》这本书从方方面面阐述了大型项目运维面临的事项,阅读这本书感受到的是扎扎实实行业经验,即便有文化方面的差异,对于工作也是有真实指导意义的。这次集体学习对于我们SRE团队成员理解工作职责有比较大的帮助,我印象最深的是这本书中也提出要勇于反馈“琐事”对于工作的影响并提升工程性工作的占比。书中建议将“琐事”控制在50%的时间比例之下,以前的时候我们通常并不会对于这类的事情进行抱怨,因为这容易被误解为工作不积极,但是针对“琐事”的抱怨可以被理解为积极的行为,是需要主动反馈的。
整体上来说,学习的过程是理论结合实践,将书中的内容跟当前特来电平台生产环境的现状相互结合,进行批判性的学习,选择适合特来电平台的做法予以吸收,后续也会根据学习经验主动改进。个人感觉这次读书活动的时间有点短,意犹未尽,后续会继续抽时间深入学习。
4.2.2 陈志康
事后总结的核心定位是:SRE 避免事故重复、保障系统可靠的必要工具,记录事故影响、应对措施、根本原因及后续任务。
4.2.3 苗强
书中有个描述"琐事过多需要主动抱怨"
更换一种更加符合中国人思路的描述就是"磨刀不误砍柴工"
Bob 大叔曾经提出一种观点,一个软件系统的价值应当由两部分组成:业务价值\架构价值.
业务价值是显性的,可见的.而架构价值往往是被忽略的.
如若不特意纠正,两者的发展曲线将是互斥的.即随着业务的增长,架构价值将逐渐归零(研发投入大于业务收入).
架构师的职责就是阻止这种事情发生,而琐事恰恰是众多架构价值减分项中,最容易被解决的部分.
我们应当主动地,积极地,与业务部门"对抗"为"重要|不紧急"的琐事优化争取机会
4.2.4 张春亮
通过阅读《SRE Google运维解密》,我深刻认识到高效运维的本质在于用工程化思维重构运维体系。要打破了传统"救火队"式的运维模式,通过系统性方法将运维从被动应对转变为主动设计。针对可靠性目标的量化管理,通过引入错误预算概念,在系统稳定性与功能迭代之间建立了动态平衡机制,将运维指标转化为可衡量的业务语言。在工作中,我们要重视自动化,自动化释放了我们运维团队的能力,使我们能更专注于设计稳定的系统架构,通过容错设计和快速恢复能力提升系统韧性。这本书最大的感触是,运维不是一个边缘支撑角色,是保障系统稳定的重要一环。相信我们通过实践SRE理念,可以进一步提升系统的稳定性,建立一套可持续演进的技术运营体系,使运维能力成为产品的核心竞争力之一。
4.3 C组
4.3.1 吴召旺
在特来电做了4年运维,之前大多是跟着故障跑,节假日公司重大会议的时候巡检 紧急扩容升配应对流量峰值,业务反馈了问题再去分析排查,总觉得运维是 被动救火的角色。但读完这本书后我刷新了新的认知,它把运维从埋头做事拉到了抬头看路的层面。
还有就是经过长时间的运维,我意识到应该重新审视生产环境和敬畏生产环境,只有分析问题的源头才能根本解决问题。
还有自动化,以前写脚本只想着解决当下问题,但书中强调的自动化重复工作、把人力投入到更有价值的优化上,正好戳中了实际工作中的痛点,比如Grafana自动切换公网,部署上自动执行,这才是运维的核心价值,当然还有更多自动化的工作等待开发。
这本书很少讲技术而是讲方法,更像是一套运维思维的重塑,让我明白如何成为一名优秀的运维工程师
4.3.2 张玉繁
读完《Google SRE 运维解密》这本书,我最大的感受是:SRE 的核心使命不是“解决问题”,而是“让问题不发生”。书中从自动化、测试、监控、容量规划、发布管理等多个维度,系统地阐述了如何通过工程化手段提升系统可靠性,让我们对日常运维工作有了更高层次的理解。
其中,“自动化是 SRE 的力量倍增器,但不是万能药”这句话给我很大启发。在实际工作中,写脚本只是自动化的起点,更重要的是在系统设计阶段就融入“自治”理念,让系统具备主动预防问题的能力,而不是事后补救。
同样,“测试的价值不在于找 Bug,而在于拦截故障”也让我深刻认识到,传统的单元测试和集成测试只是基础,真正能保障可靠性的,是生产环境下的探针测试和灰度验证。它们是防止“零 MTTR 故障”的最后防线。
整体而言,这本书带来的不仅是技术方法,更是思维方式的升级。它让我在日常工作中更加注重 架构设计的可靠性、自动化的合理性、测试的前置性,从而真正做到 以工程化手段保障系统稳定。
4.3.3 吴杨雅辉
有效的报警不在于数量,而在于质量;监控的目标不只是展示数据,更是揭示系统对业务的真实影响
4.4 D组
4.4.1 于震
系统是不断进化的,负载均衡策略、阈值也不能一成不变。在实践中,选择合适的策略与任务管理方法,并进行动态调整,是保证系统稳定性和高效性的关键。
4.4.2 冯辉
《SRE:Google运维解密》这本书给开发者带来的最大冲击,是彻底重塑了我们对“可靠性”的认知。它不再是运维团队在深夜救火时才需要关心的事,而是我们从第一行代码开始就必须内置的核心功能。拜读本书,使我更深刻的理解到开发(Dev)和运维(Ops)并非对立的两端,而是同一件事情的两个侧面。通过将工程思维贯穿于服务的整个生命周期,我们可以打造出不仅功能强大,而且真正稳定可靠的系统。这是一种将可靠性提升为工程学科的实践指南。
4.4.3 李国强
阅读《SRE: Google运维解密》,结合现有特来电开发的实践以及我们在这几年运维的经验, 目前我们的整体工作方向是符合的这本书介绍的方方面面。SRE 是一个系统的工程,而不是 简单运维操作故障处理。虽然本书成书时间较早,很多介绍的经验已经是业界共识,但是依然有很多收获,对标这本书中谷歌各类场景,我们日常工作还是有需要需要对齐,比如系统模块需要学会说不,业务的各类补偿处理在故障场景需要考虑会不会加重系统负担。需要我们在后续工作进一步完善自己的系统。
4.4.4 李泽波
卓越的可靠性不是靠英雄主义,而是源于将运维工作工程化的智慧。“拥抱风险”与“错误预算”彻底刷新了我的稳定性认知。
五、居安思危,任重道远
自7月31日架构迁移完成以来,系统响应时间显著优化,资源利用率大幅提升。
但作为SRE,我们必须清醒:硬件的“遮羞布”掩盖不了代码的“慢性病”。
我们见过太多“高可用”系统,其稳定并非源于设计,而是靠冗余和运气撑着,比如最近的亚马逊AWS的US-EAST-1区域大规模服务中断,微软Azure全球性服务中断,Cloudflare全球网络服务故障等。
真正的SRE,必须敢于在系统“看起来不错”的时候,去追问:
- “哪些隐患正在被性能掩盖?”
- “我们的SLA是否真实反映用户体验?”
- “自动化是否真的降低了认知负荷,还是只是增加了复杂度?”
因此,我们重申:
- 运维值守不是形式,是第一道防线;
- 巡检报告不是文档,是系统健康度的脉搏;
- 自动化不是工具,是应对复杂性的唯一出路。
在大模型席卷运维领域的今天,我们更应警惕“技术幻觉”——AI可以辅助排障,但不能替代对系统本质的理解;它可以生成预案,但无法替代对故障根因的敬畏。
两个月,我们读完了一本书;但真正的SRE之路,才刚刚启程。
未来,我们将把共读中提炼的“SRE原则”,固化并融入运维值守、运维巡检、故障诊断、根因分析、事故复盘等关键流程。